Beyond standard suggestions like moving your App Data to its own Unassign Drive (or now an Unraid Pool), there’s a new strategy I’ve been using for over a year that I’ve come to like: a single, high-performance and high-endurance NVMe as my primary cache.
Age-old wisdom says to use an SSD for heavy IO activities like rar unpacking, an SSD for Plex metadata, an SSD for Media, or other Share’s caching. All good suggestions when SSDs were expensive smaller, and PCIe lanes were plentiful. It was cheap to throw smaller SSDs at problems. But that came with its own cost – using PCIe/M2 slots, transferring data between them for some use cases, and managing more drives.
As we move to smaller motherboards, change our workloads around Plex, or want to take advantage of low pricing on enterprise-grade performant SSDs there are new options. Enter the Big Mac (Massive Arse Cache).
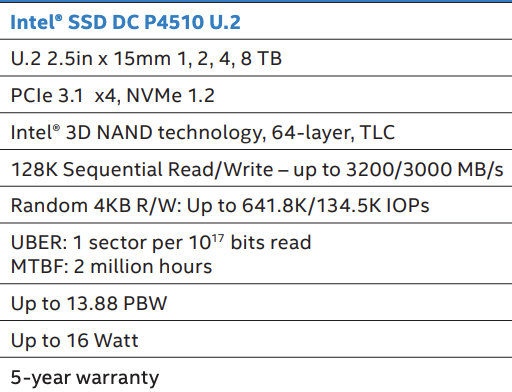
First, let’s take a look at one of my favorite drives (that I use) as my Big Mac:
The Intel P4510 is an enterprise NVMe SSD. It runs cool, it can be found cheap enough, and has incredible speed and endurance.
At a glance, working down through the specs, we can get up to 8TB (what I use but I’d suggest something more like the 4TB for most people). It uses the u2 form factor so you’ll need the $15-20 adapter. They sell an m2 to u2 adapter for $30 that you can use (never used one so I can’t recommend a specific adapter). We’ve got 3GB/s speeds – which is more than plenty for an all-in-one and quite a lot of headroom. It’s not the 7GB/s we’re seeing on newer NVMes but it’s fast enough and the price-point of these drives are hard to beat. We’ve got plenty of IOPS; the sequential is fast enough for 99% of us and the random is plenty for 99% of our uses. You can find better write-optimized IOPS but I’ve felt anything over 80-100K to be more than sufficient. And really where this drive shines is in its endurance, which measures >10PBW (or 10,000 TBW for those still measuring in TBs). Finally, the power usage is very reasonable at 16 Watts under usage. A typical SATA SSD will use around 5w and a typical consumer NVME could be up to 7-8w. So there is a power jump but you could consider that you may go from 2-3 SSDs to a single one.
Value Driver #1, #2: Fewer Drives, Faster File Movements
Looking back at my previous setup, this single drive replaces 2 of my SAS/SATA SSDs that were each 512GB/2TB. When I first moved to a single big drive, the plan was to consolidate drives and take advantage of one major benefit: internal transfer speed. When I had a drive for unpacking and a drive for Media cache, files were being transferred between disks. That’s slow in my setup, and I wanted the fastest possible path from acquisition to storage on the cache. Internal transfers are very fast. Everything is fast and within one disk, from acquisition to unpacking to moving (or hard-linking) to the right location. The bottleneck is the internal drive speed which at 3GB/s is exceptional.
Value Driver #3: A Drop Box
I think we could stop with the first two value drivers and call it a day. But a couple of months in, I found that having a large cache meant running a mover operation every night to move media from the cache to the array, resulting in my cache drive being pretty underutilized. I still had space left as the cache for all shares that used cache and media acquisition cache. I created a Swap share and set it to live only on the cache. This is a fast Dropbox-style folder I can use across my home network. The durability and size of this drive made sense to have an ephemeral little folder. I use it to transfer around ISOs, package installers, etc. A smaller value driver, for sure, but it is still one that comes in handy.
Value Driver #4: Spinning Down Disks
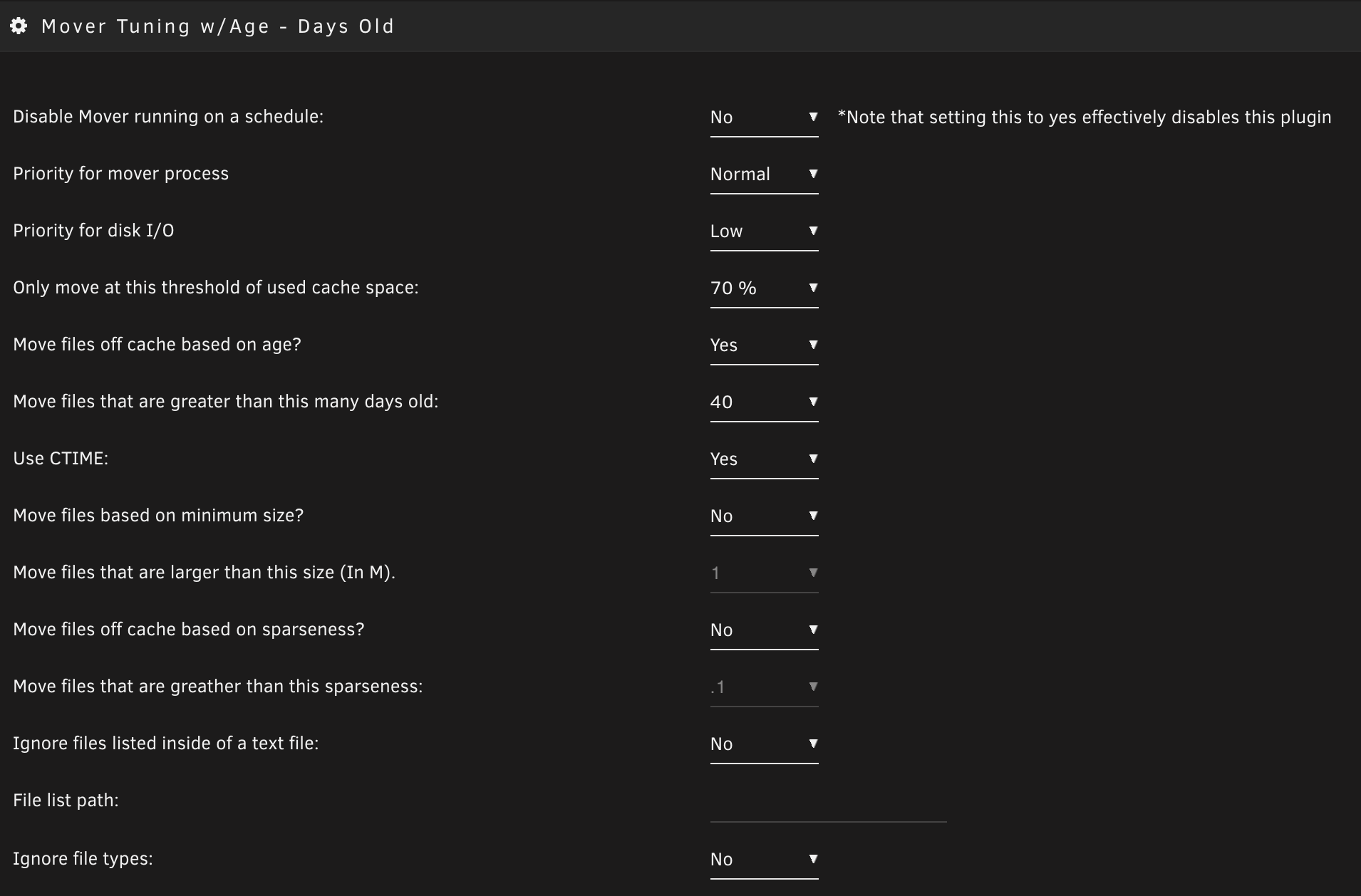
After moving to a larger cache, I started running my Unraid mover process every few days instead of every day. I had the same, why not? Well, it turned out that I could probably wait weeks to months between running mover with how much excess space I had on the cache drive. There are some downsides to this (more on that later), but I was intrigued. So 6+ months ago (from writing this post), I installed the mover tuning plugin and set the mover to only move files on the cache that were >40 days old and the cache drive was greater than 70% full. I also set all of my Unraid array drives to spin down after 2 hours of non-use. I tested this for a few weeks and was pretty surprised. It was very rare an array drive would spin up. Now and then, a bunch would spin up, though, and I’d need to figure out what would cause those spins. But after a few more days of tweaks, it became normal to see drives spin once per day or when I was accessing older media and on one the array. My drives are spun down 6+ months later, 90%+ of the time. I believe the power savings offset the wearing of spinning down disks. While I used to have more spinning disks (13+), I’ve been shrinking my array with higher-density drives. I weigh in at 9 drives now. At an average of 5w per drive, I’m saving roughly 45w when they are spun down. I’d say it’s an average 30-35w saving when you factor in spin-ups. At my power pricing per w per hour, I’ll take the $30-35 annualized savings. It ain’t much, but it’s something, and it’ll only pay better as my power rates rise and I add in more drives. I place this value driver last because for some people this won’t be a big value or worth the risks that I’ll share next!
If you’re interested in spinning down disks, the rest of this post will be about that.
Risks of a Big Cache: Shares can be unprotected for a long time
This is the biggest single risk. And it’s one worth thinking about. In my case, I have the following shares:
| Share | Before Big Mac | After Big Mac | Risk Exposure Before | Risk Exposure After |
|---|---|---|---|---|
| /mnt/user/Backups/ | Cache | Cache | 24 Hours | 24 Hours |
| /mnt/user/LTS-Books/ | Cache | Array | 24 Hours | None |
| /mnt/user/data/ | Cache | Cache | 24 Hours | ~40+ Days |
| /mnt/user/SwapSSD/ | Cache Only | Cache Only | All | All |
| /mnt/user/Games/ | Cache | Array | 24 Hours | None |
| /mnt/user/plex_swap/ | Cache | Cache | All | All |
I tried to show a few of my shares in the table and the before/after settings. I think this was a good practice, in general, to revisit exposures and audit my shares. So what’s going on? I had to evaluate all of my shares and ask which ones needed to use Unraid’s cache and which could write directly to the array. In the case of LTS-Books (Long Term Storage, Books) I felt that the files were small, and since I was not writing/reading from the share very often, I could skip the cache altogether. I did the same thing with the Games share. For SwapSSD, I already know this is a risky share, so I left it as-is. plex_swap is where I do Plex transcoding; I’d rather do that on my enterprise NVMe than my Sabrent consumer NVMe.
Here’s my 8TB NVMe SSD entry in Unraid > Main. I left in the app_data_cache pool to show I still let that live on its own:

It’s not that full right now, zooming in to see what’s on it:

Backups and data are a different story. Both had risk exposures change. Going from running mover every 24 hours meant that some shares would experience new exposures. I felt that my exposure to data loss on my Backups share could not exceed 24 hours, so something had to be done there. At first, I set the share not to use the cache. This had some other unintended side effects – backups to this share were painfully slow. For example, I back up Plex in full every week. At 40GB+ of Plex data, this went from a 6-minute task to 30+ minutes. The Plex docker is stopped during the Plex backup, which means downtime. Similarly, I backed up my App Data every week, which meant longer downtime for each docker as the backup script worked through them individually.
The steps I took to spin drives down:
- Went through each drive on the Unraid > Main page and set the spindown to 2 hours. I did not set a global amount as I have unassigned drives that I want to stay spun up.
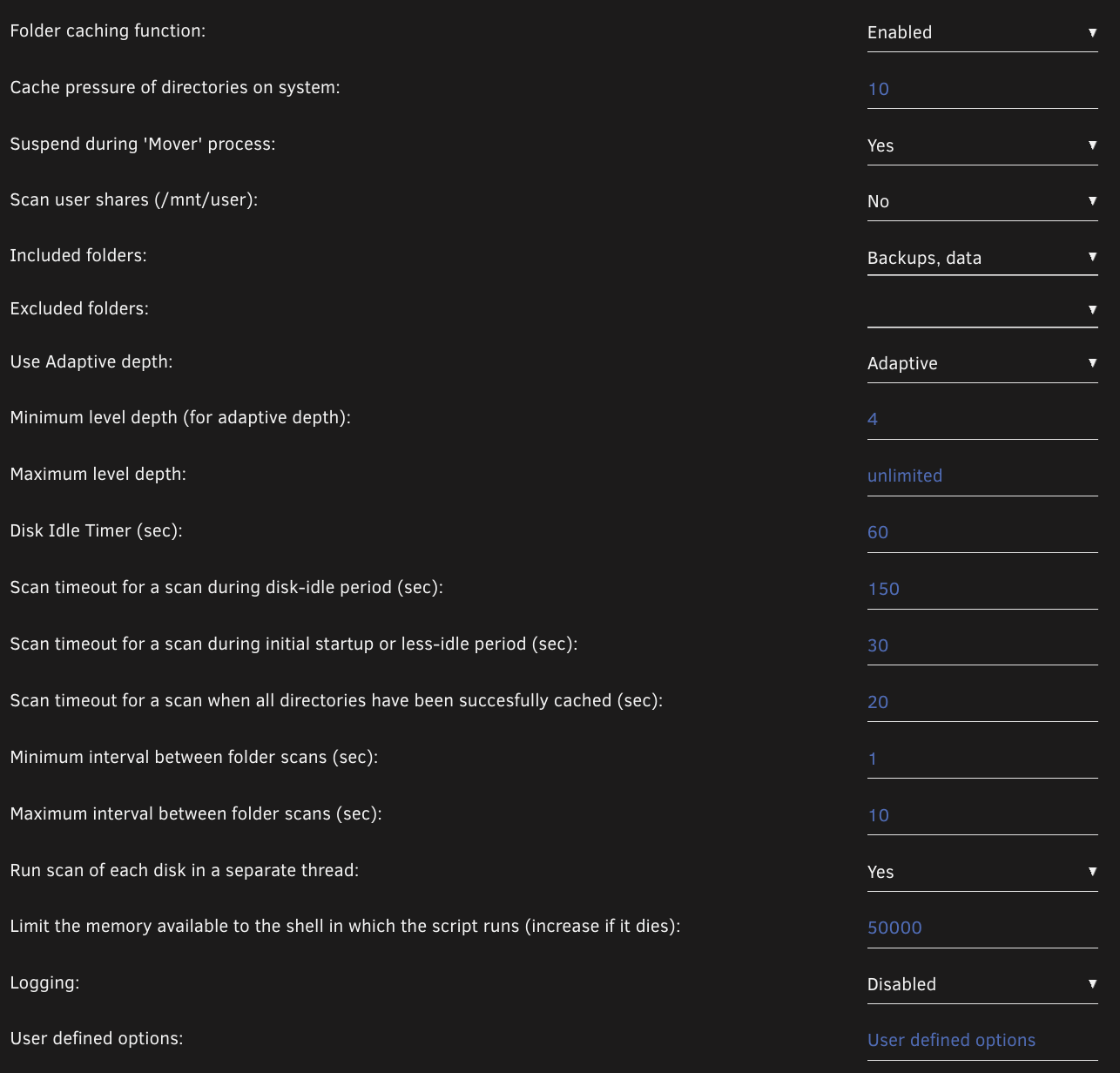
- Installed and left the default values for the Dynamix Cache Dir’s plug-in (this helps prevent spinups if an app is checking if a file exists on a drive)
- Install the mover tuning plugin and set the following settings (below)
- Set the Tunable (md_write_method) to Auto in Settings > Disk Settings. Many turn this on to achieve faster writes to the array; things speed up by having all drives spun up. Any single write to the array will spin up the entire array. Setting this to Auto will only spin up the Parity drive(s) and the target drive you’re writing to. It’s slower, but for my purposes, that’s OK.
- Added a User Script for a customer mover. This is an important step that will move files from the cache to the array for specific shares and arguably the most important aspect of this post for spinning down drives.
In talking to TRaSH, we realized if you’re using this guide from TRaSH’s website then you can just set your days count to much higher, which effectively has things living on your cache for longer. The mover script in that guide is modified and achieves something similar to what I will outline below. If you’re mixing in Usenet, using other clients besides qBittorrent, you may still want to continue reading.
Example Cache Dirs Settings
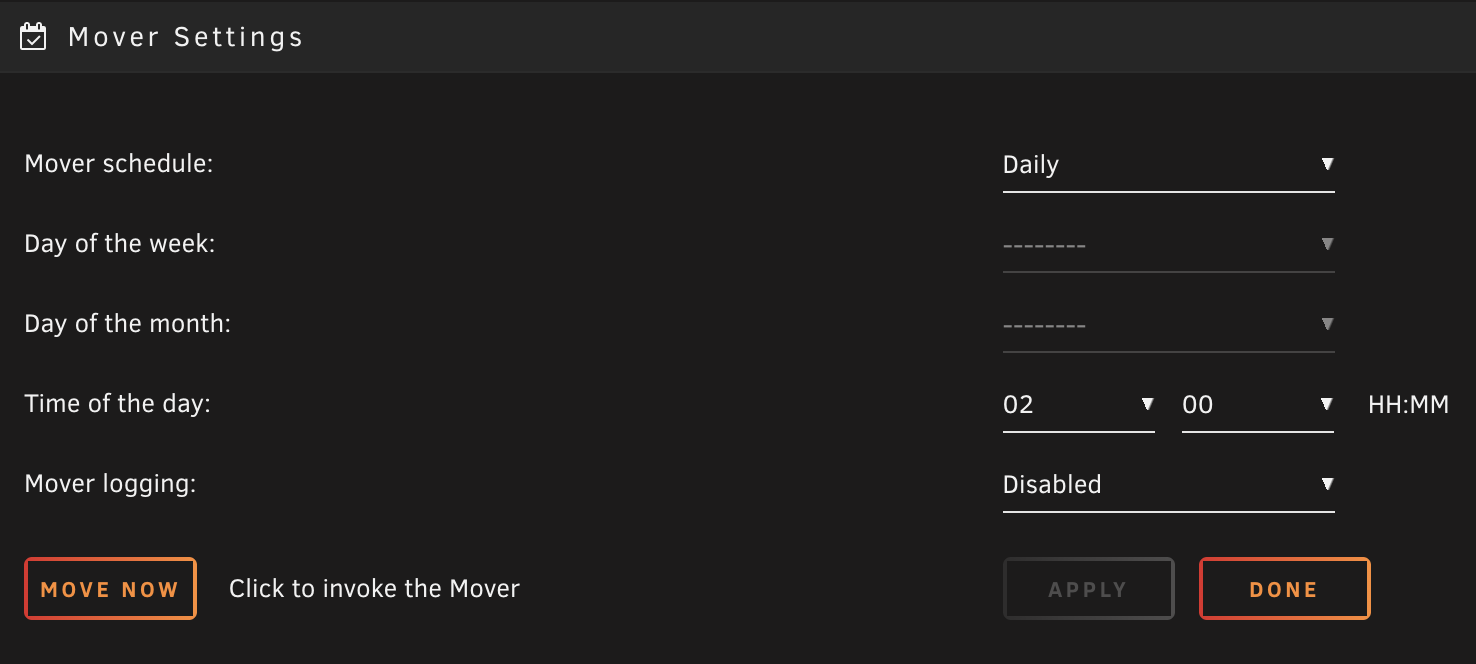
Example Mover Settings (Settings > Schedule)
Example Mover Tuning Settings (Settings > Schedule)
Example Disk Settings
User Scripts Entry
User Script
I have a script named mover_fast in Unraid’s User Scripts. This script is a modification of the official mover script. I run this in the background. The purpose of this script is to **move ALL shares’s data that have Cache set to Yes to the array. It’s the same thing Unraid’s mover does. However, because I call this explicitly, it does not respect any of the mover tuning plugin settings. That is intended and desired. Within this script, I purposely skip over the data share since I want that share to be handled by Unraid’s mover and respect the mover tuning plugin settings.
You will want to update the code below with the Shares you want fast_mover to skip. The shares skipped here will be picked up by your normal mover process. Think of this script as saying, “Do every share except for these because these have their schedule managed by another process.”
The code that does the skipping and needs modification:
if [[ $SHARE == 'data' ]]
then
echo "- Skipping share: $SHARE"
continue
fi
That’s it! That little If/Else statement will skip the data share. I only stop data from moving to the array. I do not skip data moving from the array. This is a very rare thing so I left the mover script as untouched as possible. The fast_mover will not run at the same time as another mover is running so make sure to schedule it during a different time than your regular mover.
This is tested in Unraid 6.11.x. I do not know if it works in Unraid 6.12.x or any other version!! You can see a diff between the 6.11.x mover script (with my modifications) and the 6.12.3 (latest version I have installed on another server): 6.11<>6.12 mover script diff. You can also look at the 6.11<>6.12 without my edits.
#!/bin/bash
#Copyright 2005-2020, Lime Technology
#License: GPLv2 only
# This is the 'mover' script used for moving files between a pool and the main unRAID array.
# It is typically invoked via cron.
# First we check if it's valid for this script run: pool use in shfs must be enabled and
# an instance of the script must not already be running.
# Next, check each of the top-level directories (shares) on each pool.
# If, and only if, the 'Use Cache' setting for the share is set to "yes", we use 'find' to
# list the objects (files and directories) of that share directory, moving them to the array.
# Next, we check each of the top-level directories (shares) on each array disk (in sorted order).
# If, and only if, the 'Use Cache' setting for the share is set to "prefer", we use 'find' to
# list the objects (files and directories) of that share directory, moving them to the pool
# associted with the share.
# The script is set up so that hidden directories (i.e., directory names beginning with a '.'
# character) at the topmost level of a pool or an array disk are not moved. This behavior
# can be turned off by uncommenting the following line:
# shopt -s dotglob
# Files at the top level of a pool or an array disk are never moved.
# The 'find' command generates a list of all files and directories of a share.
# For each file, if the file is not "in use" by any process (as detected by 'in_use' command),
# then the file is moved, and upon success, deleted from the source disk. If the file already
# exists on the target, it is not moved and the source is not deleted. All meta-data of moved
# files/directories is preserved: permissions, ownership, extended attributes, and access/modified
# timestamps.
# If an error occurs in copying a file, the partial file, if present, is deleted and the
# operation continues on to the next file.
PIDFILE="/var/run/mover.pid"
CFGFILE="/boot/config/share.cfg"
LOGLEVEL=0
start() {
echo "mover: lets move some stuff"
if [ -f $PIDFILE ]; then
if ps h $(cat $PIDFILE) | grep mover ; then
echo "mover: already running"
exit 1
fi
fi
if [ -f $CFGFILE ]; then
# Only start if shfs includes pools
if ! grep -qs 'shareCacheEnabled="yes"' $CFGFILE ; then
echo "mover: cache not enabled"
exit 2
fi
if grep -qs 'shareMoverLogging="yes"' $CFGFILE ; then
LOGLEVEL=1
fi
fi
if ! mountpoint -q /mnt/user0 ; then
echo "mover: array devices not mounted"
exit 3
fi
echo $$ >/var/run/mover.pid
[[ $LOGLEVEL -gt 0 ]] && echo "mover: started"
shopt -s nullglob
# This script was modified to ignore a single share, `data` but respect all other
# Unraid share's that want to move data from any cache pool to the array
# Context: `data` contains multimedia that we want to remain on the cache
# Context: and rely on Unraid's plugin mover tuning to only run mover when cache is >70% used
# Context: without forcing all other shares to leave data on cache during that time period
# Check for objects to move from pools to array
for POOL in /boot/config/pools/*.cfg ; do
for SHAREPATH in /mnt/$(basename "$POOL" .cfg)/*/ ; do
SHARE=$(basename "$SHAREPATH")
if grep -qs 'shareUseCache="yes"' "/boot/config/shares/${SHARE}.cfg" ; then
if [[ $SHARE == 'data' ]]
then
echo "- Skipping share: $SHARE"
continue
fi
echo "+ Processing share: $SHARE"
find "${SHAREPATH%/}" -depth | /usr/local/sbin/move -d $LOGLEVEL
fi
done
done
# Check for objects to move from array to pools
ls -dvc1 /mnt/disk[0-9]*/*/ | while read SHAREPATH ; do
SHARE=$(basename "$SHAREPATH")
echo $SHARE
if grep -qs 'shareUseCache="prefer"' "/boot/config/shares/${SHARE}.cfg" ; then
eval $(grep -s shareCachePool "/boot/config/shares/${SHARE}.cfg" | tr -d '\r')
if [[ -z "$shareCachePool" ]]; then
shareCachePool="cache"
fi
if [[ -d "/mnt/$shareCachePool" ]]; then
find "${SHAREPATH%/}" -depth | /usr/local/sbin/move -d $LOGLEVEL
fi
fi
done
rm -f $PIDFILE
[[ $LOGLEVEL -gt 0 ]] && echo "mover: finished"
}
killtree() {
local pid=$1 child
for child in $(pgrep -P $pid); do
killtree $child
done
[ $pid -ne $$ ] && kill -TERM $pid
}
# Caution: stopping mover like this can lead to partial files on the destination
# and possible incomplete hard link transfer. Not recommended to do this.
stop() {
if [ ! -f $PIDFILE ]; then
echo "mover: not running"
exit 0
fi
killtree $(cat $PIDFILE)
sleep 2
rm -f $PIDFILE
echo "mover: stopped"
}
case $1 in
start)
start
;;
stop)
stop
;;
status)
[ -f $PIDFILE ]
;;
*)
# Default is "start"
# echo "Usage: $0 (start|stop|status)"
start
;;
esac
Conclusion
A concluding thought… I started with a single SSD as my single cache when I first installed Unraid. I then went to multiple SSDs. I’m now using one large SSD. I have some other permutations to test and more learnings ahead of me. I won’t be surprised when I write another post about a new way of doing things a year from now. We’ll see what matters to me then. That’s the game.